LBSN综述(下)
上一篇文章介绍了LBSN的概要和从用户角度的研究内容,这篇文章我们将介绍从位置角度的研究内容。
从位置角度的LBSN研究主要分为两块:普通(General)推荐和个性化推荐。普通推荐主要遵循以下模式:trajectories->interesting locations -> popular travel sequences -> itinerary planning -> activities recommendation。个性化推荐分为user-based和location-based。
1 普通推荐
1.1 兴趣位置和旅游序列的挖掘
兴趣位置和旅游序列(travel sequence)随着时间和一些其他因素变化,因此可以从位置轨迹根据时间等因素挖掘兴趣位置和旅游序列。
在进行普通推荐时,我们要考虑两个问题:1 在确定一个位置的兴趣度时,不同用户的轨迹对兴趣度的权重不同,因为用户对这个位置的熟悉程度不同,即用户的经验不同。2 用户的经验和位置的兴趣度是相关的,并且和给定的区域有关。用户经验和位置的兴趣度对于不同的地区可能有不同的值。
1.1.2 兴趣位置的挖掘方法
首先,用户的历史轨迹通过使用基于树的层次图(tree-based hierarchical graph, TBHG)建模。分为以下两步
- 构建一个统一层次框架F,此步和上一篇文章中介绍的方法几乎相同:检测停留点,并以层次为基础将点聚类。
-
在每一层中构建位置图。在框架F的基础上,每一层中根据用户的历史轨迹,加入有向边。此步和上一篇中介绍的为用户轨迹建模的区别是此步同时考虑所有用户的历史轨迹,将所有用户的历史轨迹包含到这个基于树的层次图中。

然后,使用TBHG提出基于HITS的推断模型,该模型将用户曾访问过某个点看作用户到位置的有向边。此模型推断出两个值:位置的兴趣度和用户的旅行经验,此过程中模型考虑两个值的相互作用关系和给定的地理区域。
HITS(Hypertext Induced Topic Search)模型
此模型原先是用来进行主题下的超文本搜索的。对于一个搜索请求,HITS首先扩展搜索引擎的返回的一系列相关页面并为他们生成两种排名:authority排名和hub排名。如下图所示,authority是有很多inlink的网页而hub是有很多outlink的网页。HITS的原理是认为好的hub只想很多好的authority,同时,好的authority背很多好的hub指向。页面的authority得分就是指向他的所有的hub的总得分,而hub得分就是他指向的authority的总得分。通过一定数量的迭代,就可以获得最终的得分。HITS的主要作用是针对一个话题对页面进行排名。
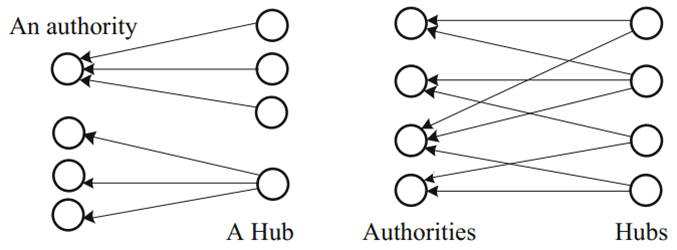
相互作用关系
将用户作为Hub,用户访问过很多地方,而位置作为Authority,位置被很多用户访问过。此时的访问就是超文本中的指向关系。
区域相关
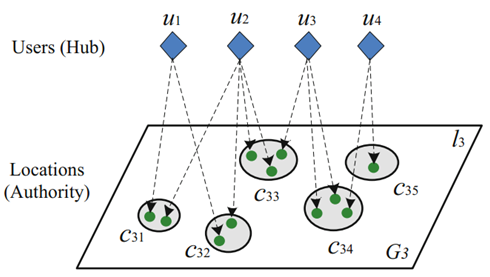
很明显,用户的经验和区域相关,比如我对南京很熟悉,但是我对北京就不熟悉。这个概念就和在HITS介绍的搜索引擎当中的搜索步骤对应,首先根据区域构建一个属于这个区域的location集合,在这个位置集合的基础上使用HITS推断模型。
位置集合选择策略
在TBHG模型中,节点(停留点聚类)可作为它的下层节点的区域。因此,可根据用户的选择的区域包括的节点,选择他们共同的唯一的上层节点(ascendant cluster)。举例如:

推断方法
给定一个区域,我们根据此区域(cluster)下面的所有位置构建邻接矩阵,xy坐标为用户和位置,内容为用户访问位置的次数。
比如,对于最顶层团C11,我们可基于所有的五个团构建邻接矩阵:

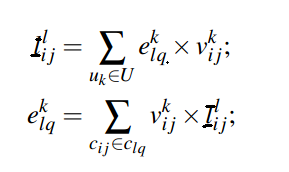
其中,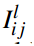 表示团Cij基于层次l的authority得分,
表示团Cij基于层次l的authority得分,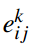 表示用户k给定区域Cij的hub得分。
表示用户k给定区域Cij的hub得分。
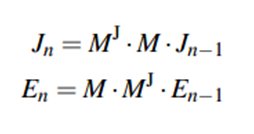
1.2.2 旅行序列(travel sequence)的挖掘方法
对于给定区域的位置序列流行度的计算,考虑两个因素:1走过这个序列的用户的旅行经验;2 属于这个序列的位置的兴趣度。
对于一个长度为2的序列,A->C,序列的流行度包括以下三个方面:
- 属于这个序列的A的authority得分(即得分乘以离开A的所有的人数中属于这个序列的比例)
- 属于这个序列的C的authority得分(乘以从A中进入C的人数站所有进入C的比例)
- 走过这个序列的用户的hub得分。
如下图:
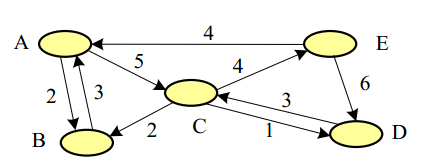
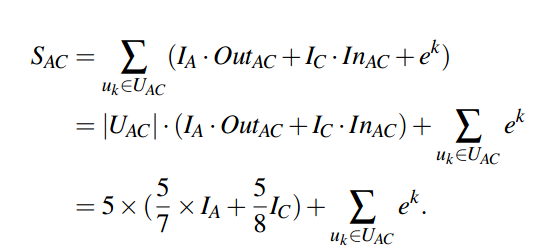
长度为3的序列的流行度为长度为2的流行度之和。
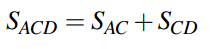
通常,计算长度为3的流行度比较有用,因为人们不会一次出行中去太多地方。
1.2 旅行线路推荐
通过获得了有趣的位置和旅行序列,可以在在不熟悉城市旅行中提供帮助,但仍有一些问题。第一,如果有很多可以去考虑的位置,用户会希望使他的旅行经验最大化。第二,旅行路线需要使用用户的当前位置、可支配时间和目的地。
以下介绍郑宇发表的相关论文中的路线推荐方法。
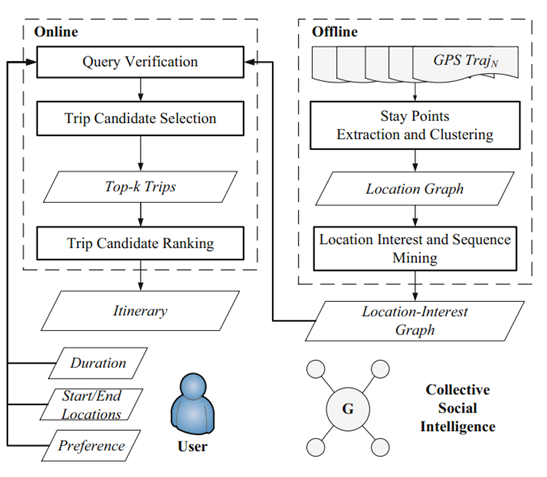
离线部分:此部分挖掘群体智慧,即痛过上一小节中介绍的方法计算位置的兴趣度和序列的流行度。
第一步:停留点的抽取和聚类,获得位置层次图。对于每个停留点在数据中有相应的进入时间和离开时间,以此可以计算出位置内的停留时间和位置间的移动时间,为预测路线花费的时间提供基础。
第二步:推断位置图中的每个位置的兴趣度,并计算长度为2的序列的流行度。
离线部分的输出为位置-兴趣度图,节点为附有兴趣度和停留时间的位置,边为人们的移动(我感觉还有序列的流行度)和移动时间。
在线部分:此部分获得用户的请求并找到最佳路线返回给用户。
第一步:请求验证。额,没啥好说的,过滤不规范输入。
第二步:此步在位置-兴趣图中找到满足用户请求的路线。
第三部:对满足请求的路线进行排名。考虑:利用时间率,停留时间率,位置的兴趣度之和,旅行序列的流行度之和。
1.3 位置-活动推荐
位置活动推荐主要是解决两个问题,如果想进行一个活动去哪里以及如果在一个地方有哪些活动。
此节由于文章写的太简陋看不懂,同时参考原参考文献《Collaborative Location and Activity Recommendations with GPS History Data》
推荐系统的架构如下:
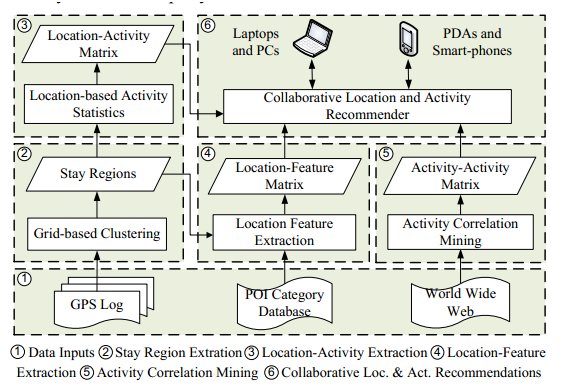
由于仅使用轨迹数据,获得的位置-活动矩阵非常稀疏,因此在此系统中加入了其他两个矩阵对推荐进行辅助,分别为位置-特征矩阵和活动-活动矩阵。
位置-活动矩阵
该矩阵中的元素为在该位置进行过的某一活动的次数。
位置-特征矩阵
此特征中,列表示category,比如餐厅、电影院等。根据POI数据库,根据位置里面的所有POI计算location的特征即类别。根据TF-IDF算法计算。
活动-活动矩阵
此矩阵中保存的是活动和活动之间的关系,获得的方法是通过两个活动名称在google等搜索引擎中检索的结果个数来评价。
协同推荐方法
总的来说,推荐算法的目的是计算出位置-活动矩阵的未知元素,该矩阵填满就可以直接进行推荐。
没看懂…,大家仔细看吧。。
2 个性化推荐
为进行个性化推荐,构建用户-位置矩阵,元素为用户到达该位置的次数,以此反映用户对该位置的偏好。在此基础上,便可以使用协同过滤技术。如:

2.1 基于用户的协同过滤
1 根据用户的历史轨迹计算用户的相似度。可根据地理空间模型,也可以根据语义空间模型。
2 位置选择
3 打分。
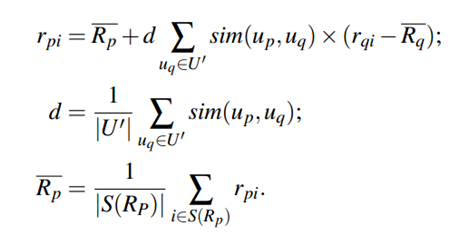
其实这个基于用户的协同过滤推荐方法和传统的协同过滤的唯一区别就是第一步在计算用户的相似度时根据用户的历史轨迹,而不是用户对item(locationi)的打分,但是历史轨迹又体现了对location的偏好,其实还是一个东西。
2.2 基于item的协同过滤
基于用户的协同过滤在用户数量较大的情况下会需要非常多的计算资源,而location相对来说不会增加太多。
2.2.1 挖掘位置间的关联
位置间的关联不仅仅是类别、距离上的关联,还要从用户行为上体现。比如,人们吃完饭可能会想去看电影,则餐厅和电影院也有一定的关联性。
位置的关联可以用于广告牌投放地的选取、旅游推荐等。
计算位置间的关联主要考虑以下因素:
- 用户访问者两个位置的数量以及用户的经验。
-
包含这两个位置的访问序列。
- Cor(A,B)不等于Cor(B,A)
- 在一个序列中,AB的访问越接近,两个位置越相关。
可使用以下公式定义AB的关联度:
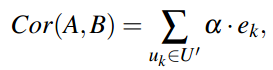
Ek表示用户k的旅行经验,a表示两个位置的间隔距离。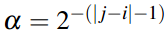
我:每个用户不可能只有一个轨迹,对于一个用户多个轨迹这里面好像没有体现,好像只考虑了每个用户的一个轨迹。
2.2.2 The Slope One Algorithm
Slope One算法是基于item评分的算法,此位置推荐算法就是在此算法上面的一个小小的改进。
对于一个评价矩阵,该算法首先计算不同item之间的差值(deviation):
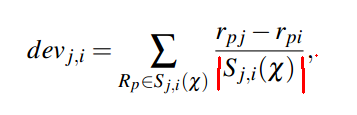 (计算所有对i和j都进行评价了的用户的i和j之间的差值的平均值)
(计算所有对i和j都进行评价了的用户的i和j之间的差值的平均值)
若要预测j的打分,则将根据其他item预测到的打分求平均值。
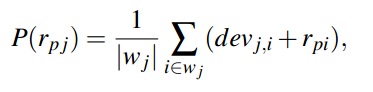
(改进)为了更加准确,在根据i预测j的打分时,同时考虑同时评价了i和j的用户数,并作为权值,求加权平均:
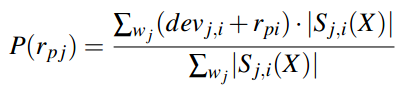
2.2.3 位置推荐打分
位置推荐算法和Slope One算法的唯一区别是不用同时评价了i和j的用户数作为权值,而使用两位置之间的关联作为权值:
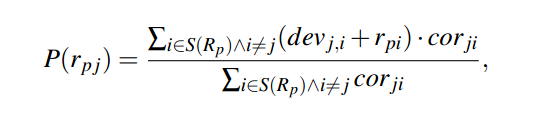
因为在我们的模型中,过滤矩阵的元素就是用户到达位置的个数,因此使用用户数作为权值就不准确了。