LBSN综述(上)
本文是根据郑宇大婶的文章做的总结。主要参考文献为书籍——Computing with Spatial Trajectories中的最后两章。
此篇文章介绍了LBSN介绍、轨迹建模以及从用户角度的一些研究内容。
下篇将介绍从位置角度的研究内容。
1 LBSN介绍
LBSN不仅仅是将位置信息嵌入到社交网络,而是根据位置信息推导出新的社会结构。这里的物理位置包括即时位置和某一段时间的位置历史。此外,依赖关系不仅仅包括梁用户同时出现在相同的位置或具有相同的位置历史(location history),同时包括从用户的位置信息数据中挖掘到的知识(兴趣、行为和活动等)。
1.1 LBSN服务
位置服务可分为三种类型:
基于位置的标签媒体(Geo-tagged-media-based):位置作为媒体的一个特征,组织和丰富传媒内容。媒体仍然是主体。
点位置(Point-location-driven):分享用户当前位置,比如签到。位置(点)是主体,体现了多用户之间的依赖,同时用户生成的内容看作一种特征。
轨迹(Trajector-centric):点和线。同时添加入tags、photo。tips等。
下图是三种服务类型的比较:

论文上说:第一二种形式可以转化为第三种形式,第三种形式的方法也可以用于第一二种形式。下面主要介绍第三种形式的算法。
作者:我对此感到怀疑,我觉得即使转化为3,也需要较大的修改,这些方法可能需要大幅度修改。文中说可以将1、2转化为3,但是是由于稀疏性,需要使用聚集和协同的方法,但没有说如何使用这些方法。
1.2 LBSN研究方法和研究方向
基于轨迹数据,可构造三种图:
location-location:点表示location,边表示一些用户连续访问这两个location。边的权重表示两位置的关联性。
user-location: 两种点;从用户到location的边表示用户访问过location(权)。
user-user :表示用户之间的社会关系(1.直接的,2.通过位置数据推导出的)
通过以上三种图,我们可以分别从用户和位置的角度对用户和位置以及他们之间的关系进行理解。即以用户/位置为重点,另一个辅助。
从用户的角度:通过位置理解用户。
- 估计用户间的相似度。2.3节
- 找到一个区域的本地expert。2.4节
- 社区发现。2.4节
从位置的角度:通过用户信息理解位置。
-
普通(Generic)旅游推荐:
- 挖掘最有趣的位置:找到最受欢迎的位置和行驶序列。
- 路线计划:根据用户的要求为用户推荐旅游路线。
- 位置-活动推荐:1在某一个location最火爆的活动。2针对某一活动最受欢迎的地点。
- 基于用户的协同过滤
- 基于位置(同基于item的系统推荐)
<li>
<li>事件发现</li>
2 位置历史建模
要对以上研究,首先要对用户的位置历史进行建模。郑宇自08年发表了一系列文章,提出了一个新的模型,模型考虑了不同用户间的位置历史间的比较,模式:"传感器数据->地理位置"->语义"。此模型有两个优点:1 同时对个人和多人的历史位置建模,使其具有可比较性和可计算性。2 分别基于地理空间和语义空间建模,可以更好的理解用户的行为和兴趣。
直接通过原始的GPS数据对用户位置历史进行测量非常困难,因为原始的GPS数据有一定的误差,而且通过固定的阈值来确定用户是否在一个位置常常是武断的。因此,我们要将原始的历史数据转换成可计算的位置序列,比如:A->B->C。即使如此,根据用户地理空间上的移动轨迹对理解用户兴趣和行为也是不够的,将语义引入可获得更多的知识,即将"A->C"转化为"公园->商场"。
2.1 地理位置模型
此节提出了一个统一模型框架用来在地理空间上对用户的位置历史进行建模,叫层次图(hierarchical graph)。此框架包括一下三个步骤:
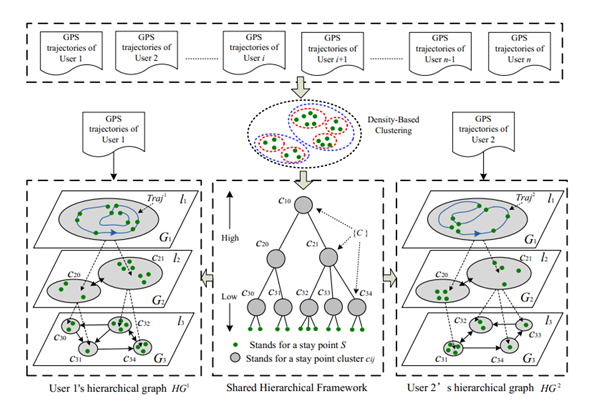
图1 地理空间上的用户位置历史建模框架
2.1.1 重要地点检测(Detecting Significant Places)
重要低点表示一个用户可进行有意义行为的位置,一般用户只会在这种位置上停留。检测重要地点的方法一般是根据时间和空间的一些规则,从GPS坐标序列中提取一些位置。
一般来说,我们希望从以下两种情况检测到一个重要地点,1用户进入一个建筑物而丢失掉了GPS信号;2 用户在一个地位空间区域停留的时间超过一个阈值。
停留点(重要地点)的检测方法:在一个轨迹中,如果两个点间的轨迹(Pi->…Pj)(不一定连续)之间的所有的点之间的距离小于一个阈值(对于所有的i<=k<j,dis(Pk,Pk+1)<阈值d),而两点间时间大于一个阈值(Int(Pi,Pj)>阈值t) ,则这些点构成了一个停留点(Stay Point)。
下图说明了停留点的检测方法:对于一个轨迹(p1->p2->…->p7),在B)图中可以看出,P1构成一个单独的点。转移到P2,发现P2,P3和P4与P2之间的距离小于阈值,如果P2和P4之间的时间间隔大于阈值t,则这三个点构成一个停留点,转到P4,发现P5和P6也符合以上时空规则(P4/P5/P6间距离小于阈值d,P4、P6的时间间隔大于阈值t),将P5和P6引入到这个停留点。最终,我们获得P2到P6都属于一个停留点。
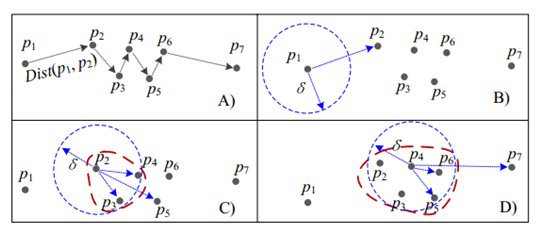
文中还是用了一定的篇幅说明了选取距离阈值d为200m,时间阈值t为15min是一个比较合适的选择。
2.1.2 构造统一框架(Formulating a Shared Framework)
虽然通过处理单个用户的历史轨迹可以获得用户的停留点,但是不同的用户在同一个位置可能表现为不同的停留点,如两个用户从不同的入口进入同一个商场。
统一层次框架如图1所示,框架将不同用户的停留点统一聚类,不同的类别表示一个位置/区域,不同的层次表现了不同的位置大小粒度。
这样,统一层次框架为不同用户提供了重构它们的位置历史的统一的框架,用户的位置历史可以基于这个框架表示。
2.1.3 构建位置历史
根据构造的统一框架,将停留点在不同层次上映射至聚类点。用户的历史轨迹像一个层次图,有两个结构构成:层次结构和每一层次上面的图。
2.2 语义位置模型
此节的目的是将用户的历史轨迹从地理空间映射至语义空间,这样可以更好的理解用户兴趣,也可以比较在地理空间没有交集的用户(两个城市)。
此方法扩展了地理位置建模的方法,主要也包括三步,与地理位置建模方法对应,主要的不同在于第一步。
2.2.1停留点表示(Stay Point Representation)
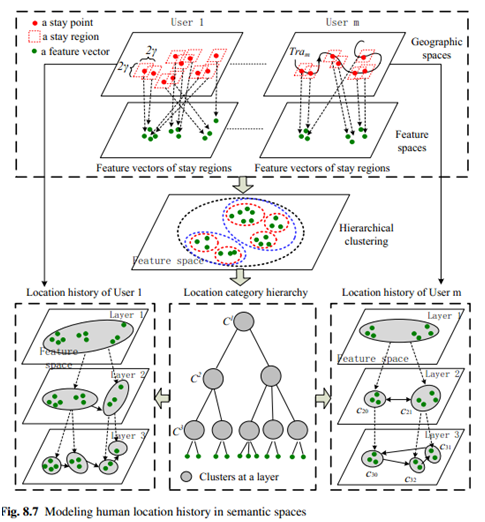
这一步是试图描述停留点的语义。但是由于GPS定位的误差以及兴趣点(point of interest, POI)的密集,有些建筑物里面甚至有很多类型的POI(比如德基广场),这样就很难对一个停留点进行语义描述。
因此,文章首先将停留点扩展为停留区域(stay region),然后根据此区域中的POI构建一个特征向量来表示这个停留区域。使用TF-IDF(term frequency-inverse document frequency)算法计算停留区域中的POI类别对此区域的表示能力,此区域中该类别的POI越多,其他区域中该类别的POI越少,则该类POI对该区域的表示越重要。
注:此处的停留点应该是首先使用2.1.1节计算的停留点,然后通过位置POI数据库,计算各停留点的POI特征向量。
特征向量的定义如下:

2.2.2 构建统一语义框架
这一步将停留区域根据特征向量使用聚类的方法将停留区域分为不同的团(Group),在同一个团下面的停留区域认为是一个具有相同语义类型的位置。然而,由于在语义层面上位置仍然是具有层次结构的,因此我们将语义位置也建模为层次结构模型,就像2.1.2一样。如下图所示。
2.2.3 构建个人历史轨迹
2.3 用户相似度挖掘(从用户的角度)
在LBSN中,存在两种用户关系,一种是传统社会网络的连接关系,还有一种是通过位置数据获得的用户关系。第二种社会关系扩展了传统的社交网络,同时,这种社会关系一般基于用户的历史轨迹的相似性获得。通过历史轨迹挖掘到的用户间的相似性可以有很多用途,比如朋友推荐、社区发现和个性化位置推荐等。
在郑宇的一系列文章中,用户的相似度计算分为两个步骤:
- 对于两个用户,在每一层次的图中找到一组相似的序列。相思序列指两人以相同的顺序和相同的时间间隔访问某组地点。
- 基于相似序列,计算两人的相似度,主要考虑以下三个因素:
- 用户移动的位置序列,相似序列越长,两人越相关。
- 层次属性。相似序列的层次越高(由上向下),即粒度越小,用户越相似。
- 位置的流行度:相似序列的位置越流行,用户相似度越低。
此框架以用户的位置历史(位置层次图)为输入,用户的相似度为输出。
2.3.1 相似序列检测
文中介绍了轨迹匹配(Travel Match)和最大轨迹匹配的概念,总的来说寻找轨迹匹配就是根据两个轨迹中同一位置以及位置的时间间隔判断,而最大轨迹匹配就只在轨迹中能找到的最大的轨迹匹配(额,有点废话),我们计算用户相似度用到的就是最大轨迹匹配。注意,轨迹匹配不要求位置是连续的,可以使地理空间上的或语义空间上的。
注:两条轨迹可能存在多个最大轨迹匹配。此最大轨迹匹配并不是要求最长的,而是要求前面没有,后面没有,中间没有即可。
由于要考虑时间因素,传统的最大序列匹配算法不能直接使用,文中也提出了一个最大轨迹匹配算法。(具体算法查看资料)
首先找到长度为1的匹配,然后将这些匹配作为图中的边构建前驱图,图中点表示同时出现在两个轨迹中的点。然后在前驱图中找到最长路径(并不要求长度最长,只要该路径前面和后面没有节点),则前驱图中的路径就对应相应的最大轨迹匹配。
2.3.2 计算用户相似度
在检测到两用户最大轨迹匹配之后,可根据位置的流行度、顺序属性和层次结构计算两用户间的相似度。
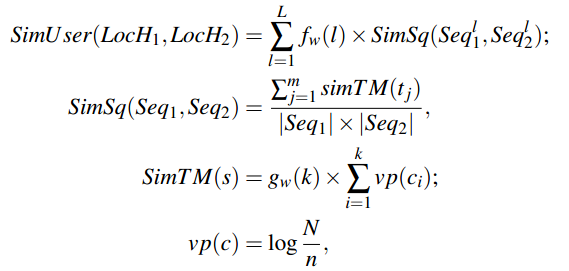
附:N是所有用户的数量,n是访问过位置c的用户数量。
解释:给定历史轨迹LocH1和LocH2,两轨迹间的相似度定义为轨迹图的不同层次的相似度之和,fw(l)=2^(l-1),l表示轨迹图层次,层次越高,权重越大。
某一层次的轨迹相似度表示为不同最大轨迹匹配的相似度之和,m为最大匹配的数量。同时,使用两轨迹的长度对其进行规格化。
最大轨迹匹配的相似度表示为包含在匹配中的地点的流行度。Gw(k)=2^(k-1)。匹配中的位置越不流行,匹配的位置数量越多,则相似度越大。
附:Gw(k)使用指数的原因是实验发现随着最大匹配序列数的增加,最大匹配成指数减少。
2.4 朋友推荐和社区发现
计算了用户之间的相似度以后,我们可以分层次的将用户聚类成团(cluster),每个团表示一群兴趣相同的用户,不同的层次表示兴趣粒度不同。同时,我们可以在每一个团中找到一个代表,可以通过找在这个团中和其他用户的相似距离最近的点作为此团的代表。
使用层次结构有两种好处:1)可更快的查询相似用户(只需要查询同一团中的用户)。2)更快的插入新用户。只要迭代的计算不同层次的团中的代表用户和新用户的相似距离即可。
由于以下三种问题,朋友推荐和社区发现仍然是一个需要解决的问题。
-
公开的数据集
- The reality mining dataset MIT
- GeoLife Microsoft
- 调查问卷
- 从社会关系中抽取
<li>
<li>评价方法</li>