K-means聚类算法
k-means聚类算法是一种无监督学习,无监督学习和有监督学习的区别是有监督学习的原数据有一个标签(label)y,而无监督学习仅仅是一系列的训练集{x1,x2,…xm}。
K-means聚类算法的思想是:首先确定要聚类为k个类,并随机初始化k个聚类的中心点,这些中心点代表着当前步骤中属于该类的训练元素的中心点。然后在每一步中计算属于当前中心点的类的训练集元素,然后根据这些元素更新相应的中心点。
正式定义的算法如下:

下图是收敛过程的例子
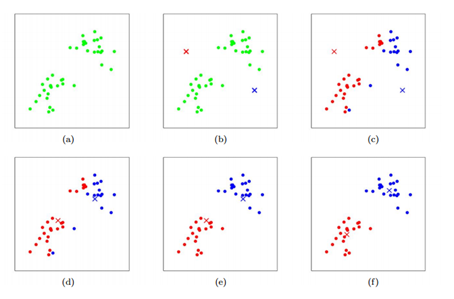
收敛问题
K-means算法是确定收敛的,我们可以定义函数J:
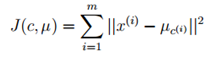
k-means算法希望使函数J的最小化,而在收敛过程中,函数J不断减小,一旦函数J不变,则k-means算法完成。
函数J不是一个凸函数,因此K-means不能保证全局最优,可以尝试使用多次K-means算法,然后找到一个最优值。
使用k-means算法时,首先要选择聚类数量,有一些算法可以自动选择类的数量,在使用k-means算法时,可以随机选择类的数量,多次运行算法,然后找到一个最合适的数量。注:类的数量一般来说比较模糊。