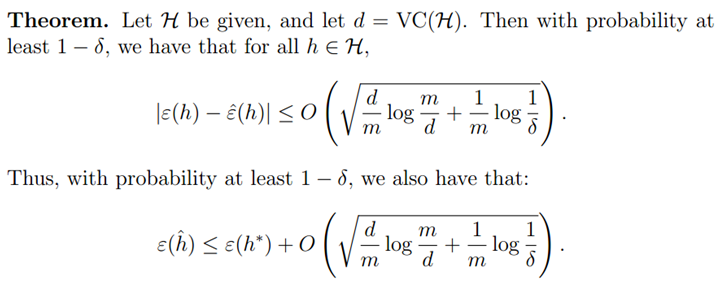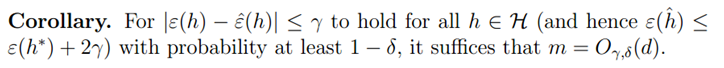微软亚洲研究院基于GPS数据展开的研究工作,取得了另学术界瞩目的成就。从2008年开始每年都在顶级的计算机类会议上有文章发出,掀起了研究GPS数据智能化处理的热潮。
他们的工作由谢幸研究员和郑宇研究员主导。实验数据采集主要有两个工程:
1、Geolife工程使用的,170多个志愿者4年左右的GPS轨迹;
2、北京市2万多出租车约3个月的行驶轨迹。
参见:http://research.microsoft.com/en-us/projects/geolife/
个人将近年来该小组发表的论文做了下整理,归纳其研究脉络如下(个人愚见,仅供拍砖,前面序号按照文章发表时间倒序排列,时间排列文献全表见最后的“参考文献”部分):
阶段一: GPS+webGIS:(GPS数据在GIS地图上的灵活展示和使用)
41、(生成用户日志,帮助用户回忆),Searching Your Life on Web Maps,SIGIR2008
42、(GeoLife1.0,在地图上管理自己的GPS日志)GeoLife:Managing and Understanding Your Past Life over Maps,MDM08
阶段二:GPS数据的简单挖掘(出行方式,用户轨迹的相似性,关联规则,异常行为,群组发现)
40、(理解用户行为),Understanding User Behavior Geospatially,计算机通信2008
36、(出行模式:步行,公交,驾驶)Learning Transportation Mode from Raw GPS Data for GeographicApplication on the Web,www2008
37、(理解移动特性),Understanding mobility based on GPS data,ubicom2008
38、(基于轨迹挖掘用户相似性)Mining user similarity based on location history,GIS2008
33、(挖掘有趣位置及旅行顺序)Mining Interesting Locations and Travel Sequences From GPSTrajectories,WWW 2009
34、(挖掘个人生活模式)Mining Individual Life Pattern Based on Location History,MDM 2009
35、(GeoLife生活模式),GeoLife2.0: A Location-Based Social Networking Service,MDM2009
30、(挖掘位置间的关联),Mining Correlation Between Locations Using Human Location History,GIS 2009
29、(基于GPS轨迹发现用户交通模式:行走、驾车、公交、地铁),Understanding transportation modes based on GPS data for Webapplications,ACMTransaction on the Web,2010
23、(学习位置间的关联)Learning Location Correlation from GPS trajectories,MDM2010
9、(交通异常,前一个版本)Discovering Spatio-Temporal Causal Interactions in Traffic DataStreams,sigkdd2011
1、群组发现(提出了一个群组发现加速的数据结构):A Framework of Traveling Companion Discovery on Trajectory DataStreams,ICDE2012
阶段三:结合外部信息,提供基于云的LBS服务
27、(计算机学会刊文)Enabling smart location-based services by mining GPS traces,Communication of China ComputerFederation2010
28、(基于云的位置服务)Location-Based Services on the Cloud,Journal on Digital Mobile Era 2010
10、(基于云的,融合多种信息,探寻用户习惯的发现)Driving with Knowledge from the Physical World,SIGKDD 2011
阶段四:同协同过滤等算法结合实现位置、活动的推荐
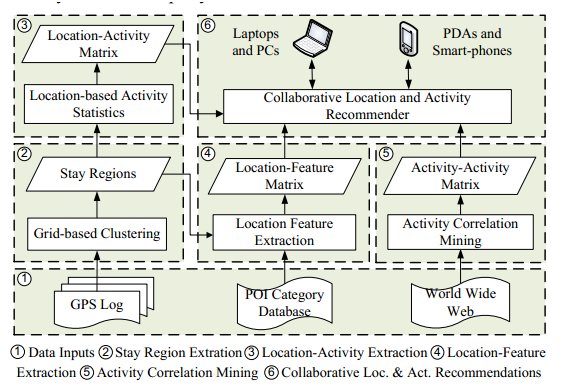
24、(位置和活动推荐)Collaborative Location and Activity Recommendations With GPS HistoryData,WWW 2010
22、(基于用户的推荐,旅游景点和行程)Collaborative Filtering Meets Mobile Recommendation: A User-centeredApproach, AAAI2010
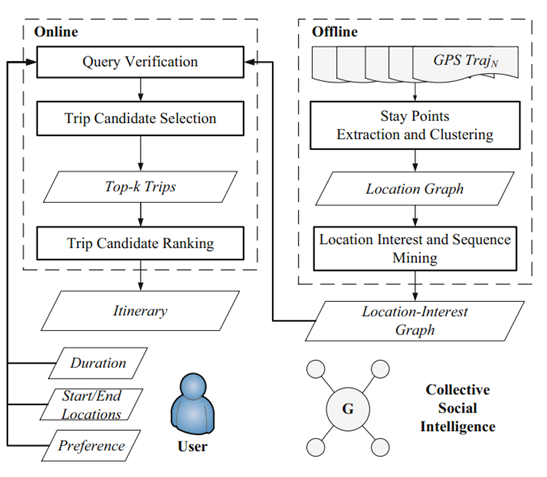
20、(前期版本,智能的行程推荐)Smart Itinerary Recommendation based on User-Generated GPSTrajectories,UIC2010
21、(GeoLife,智能生活,双层网络),GeoLife: A Collaborative Social Networking Service among User,location and trajectory,IEEE Data(base) Engineering Bulletin
14、(旅游推荐,较全面的工作),Learning travel recommendations from user-generated GPS traces, ACM Transaction onIntelligent Systems and Technology,2011
15、(根据单个轨迹推荐位置和朋友),Recommending friends and locations based on individual locationhistory,2011
12、(个人行程推荐,最初版本),Social Itinerary Recommendation from User-generated Digital Trails,Personal and Ubiquitous Computing
2、热点旅游位置推荐、周边活动发现(第二次发表:协同过滤):Towards Mobile Intelligence: Learning from GPS History Data forCollaborative Recommendation, Artificial Intelligence Journal,2012-04-29
阶段五:引入语义轨迹,泛华推荐和相似性算法
19、(利用语义轨迹,发现相似用户),Finding Similar Users Using Category-Based Location History,GIS2010
3、(语义轨迹历史)基于GPS推到用户的社会关系:InferringSocial Ties between Users with Human Location History,Journal of Ambient Intelligence andHumanized Computing
阶段六:根据出租车数据,实现智能化驾驶
16、(根据出租车历史,指导行驶方向)T-Drive: Driving Directions Based on Taxi Trajectories,GIS,2010
17、(出租司机,灵活驾驶)Drive smartly as a taxi driver,UIC2010
13、(推到出租车行驶状况),Inferring Taxi Status Using GPS Trajectories,2011
6、出租车数据探测城市的异常交通:On Mining Anomalous Patterns in Road Traffic Streams:2011International Conference on Advanced Data Mining and Applications
7、(基于出租数据的城市规划,计算)Urban Computing with Taxicabs,
8、(寻找下一个旅客)Where to Find My Next Passenger?Ubicom2011
4、基于时间关系图发现出租车行驶路线:T-Drive: Enhancing Driving Directions with Taxi Drivers'Intelligence,IEEETransactions on Knowledge and Data Engineering (TKDE)
(贯穿)轨迹的预处理类工作:
39、(灵活的时空索引),A Flexible Spatio-temporal Indexing Scheme for Large-scale GPS TrackRetrieval,2008
32、(基于客观需求的,轨迹简化策略,方向变化的位置信息量越大)Trajectory Simplification Method for Location-Based SocialNetworking Services,SIGSPATIAL GIS workshop on location-based social networks,2009
31、(稀疏采样轨迹的地图匹配)Map-Matching for Low-Sampling-Rate GPS Trajectories,GIS2009
26、(Top-k区域查询)AnsweringTop-k Similar Region Queries,DASFAA 2010
25、(基于位置点,搜索轨迹)Searching Trajectories by Locations: An Efficiency Study,SIGMOD
18、(发现数据库中的相似记录),Detecting Nearly Duplicated Records in Location Datasets,GIS2010
11、(给定一组点,检索k个最近邻的点)Retrievingk-Nearest Neighboring Trajectories by a Set of Point Locations,SSTD2011
5、低采样轨迹的不确定性处理(比地图匹配性能更好):Reducing Uncertainty of Low-Sampling-Rate Trajectories, ICDE 2012
参考文献:(按照时间降序,从新到旧排列)
2012
1、群组发现(提出了一个群组发现加速的数据结构):A Framework of Traveling Companion Discovery on Trajectory DataStreams,ICDE2012
2、热点旅游位置推荐、周边活动发现(第二次发表:协同过滤):Towards Mobile Intelligence: Learning from GPS History Data forCollaborative Recommendation, Artificial Intelligence Journal,2012-04-29
3、(语义轨迹历史)基于GPS推到用户的社会关系:InferringSocial Ties between Users with Human Location History,Journal of Ambient Intelligence andHumanized Computing
4、基于时间关系图发现出租车行驶路线:T-Drive: Enhancing Driving Directions with Taxi Drivers'Intelligence,IEEETransactions on Knowledge and Data Engineering (TKDE)
5、低采样轨迹的不确定性处理(比地图匹配性能更好):Reducing Uncertainty of Low-Sampling-Rate Trajectories, ICDE 2012
2011:
6、出租车数据探测城市的异常交通:On Mining Anomalous Patterns in Road Traffic Streams:2011International Conference on Advanced Data Mining and Applications
7、(基于出租数据的城市规划,计算)Urban Computing with Taxicabs,
8、(寻找下一个旅客)Where to Find My Next Passenger?Ubicom2011
9、(交通异常,前一个版本)Discovering Spatio-Temporal Causal Interactions in Traffic DataStreams,sigkdd2011
10、(基于云的,融合多种信息,探寻用户习惯的发现)Driving with Knowledge from the Physical World,SIGKDD 2011
11、(给定一组点,检索k个最近邻的点)Retrievingk-Nearest Neighboring Trajectories by a Set of Point Locations,SSTD2011
12、(个人行程推荐,最初版本),Social Itinerary Recommendation from User-generated Digital Trails,Personal and Ubiquitous Computing
13、(推到出租车行驶状况),Inferring Taxi Status Using GPS Trajectories,2011
14、(旅游推荐,较全面的工作),Learning travel recommendations from user-generated GPS traces, ACM Transaction onIntelligent Systems and Technology,2011
15、(根据单个轨迹推荐位置和朋友),Recommending friends and locations based on individual locationhistory,2011
2010
16、(根据出租车历史,指导行驶方向)T-Drive: Driving Directions Based on Taxi Trajectories,GIS,2010
17、(出租司机,灵活驾驶)Drive smartly as a taxi driver,UIC2010
18、(发现数据库中的相似记录),Detecting Nearly Duplicated Records in Location Datasets,GIS2010
19、(利用语义轨迹,发现相似用户),Finding Similar Users Using Category-Based Location History,GIS2010
20、(前期版本,智能的形成推荐)Smart Itinerary Recommendation based on User-Generated GPSTrajectories,UIC2010
21、(GeoLife,智能生活,双层网络),GeoLife: A Collaborative Social Networking Service among User,location and trajectory,IEEE Data(base) Engineering Bulletin
22、(基于用户的推荐,旅游景点和形成)Collaborative Filtering Meets Mobile Recommendation: A User-centeredApproach, AAAI2010
23、(学习位置间的关联)Learning Location Correlation from GPS trajectories,MDM2010
24、(位置和活动推荐)Collaborative Location and Activity Recommendations With GPS HistoryData,WWW 2010
25、(基于位置点,搜索轨迹)Searching Trajectories by Locations: An Efficiency Study,SIGMOD 2010
26、(Top-k区域查询)AnsweringTop-k Similar Region Queries,DASFAA 2010
27、(计算机学会刊文)Enabling smart location-based services by mining GPS traces,Communication of China ComputerFederation2010
28、(基于云的位置服务)Location-Based Services on the Cloud,Journal on Digital Mobile Era 2010
29、(基于GPS轨迹发现用户交通模式:行走、驾车、公交、地铁),Understanding transportation modes based on GPS data for Webapplications,ACMTransaction on the Web,2010
2009
30、(挖掘位置间的关联),Mining Correlation Between Locations Using Human Location History,GIS 2009
31、(稀疏采样轨迹的地图匹配)Map-Matching for Low-Sampling-Rate GPS Trajectories,GIS2009
32、(基于客观需求的,轨迹简化策略,方向变化的位置信息量越大)Trajectory Simplification Method for Location-Based SocialNetworking Services,SIGSPATIAL GIS workshop on location-based social networks,2009
33、(挖掘有趣位置及旅行顺序)Mining Interesting Locations and Travel Sequences From GPSTrajectories,WWW 2009
34、(挖掘个人生活模式)Mining Individual Life Pattern Based on Location History,MDM 2009
35、(GeoLife生活模式),GeoLife2.0: A Location-Based Social Networking Service,MDM2009
2008
36、(出行模式:步行,公交,驾驶)Learning Transportation Mode from Raw GPS Data for GeographicApplication on the Web,www2008
37、(理解移动特性),Understanding mobility based on GPS data,ubicom2008
38、(基于轨迹挖掘用户相似性)Mining user similarity based on location history,GIS2008
39、(灵活的时空索引),A Flexible Spatio-temporal Indexing Scheme for Large-scale GPS TrackRetrieval,2008
40、(理解用户行为),Understanding User Behavior Geospatially,计算机通信2008
41、(生成用户日志,帮助用户回忆),Searching Your Life on Web Maps,SIGIR2008
42、(GeoLife1.0,在地图上管理自己的GPS日志)GeoLife:Managing and Understanding Your Past Life over Maps,MDM08
转自http://blog.csdn.net/yumengkk/article/details/7523223

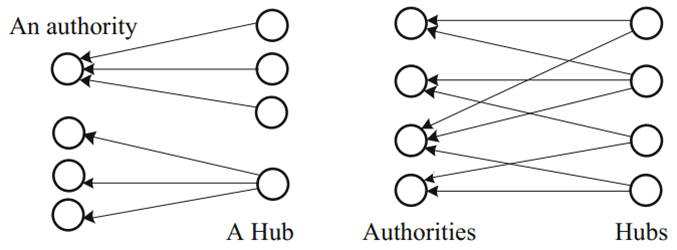
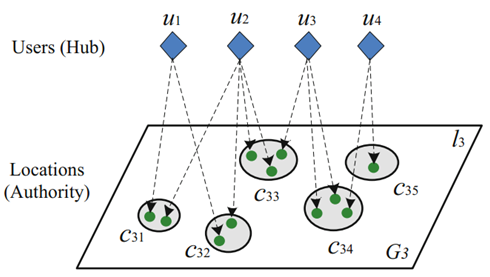


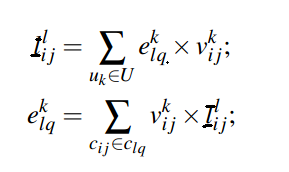
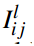 表示团Cij基于层次l的authority得分,
表示团Cij基于层次l的authority得分,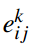 表示用户k给定区域Cij的hub得分。
表示用户k给定区域Cij的hub得分。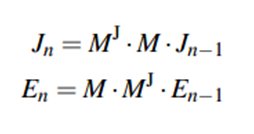

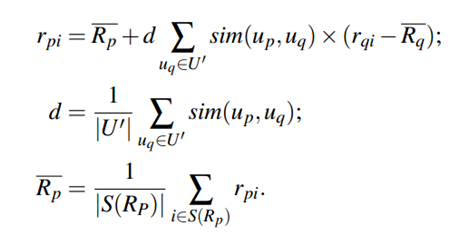
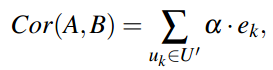
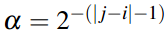
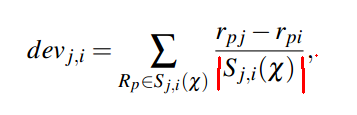 (计算所有对i和j都进行评价了的用户的i和j之间的差值的平均值)
(计算所有对i和j都进行评价了的用户的i和j之间的差值的平均值)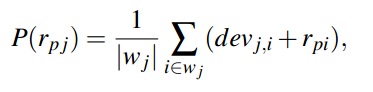
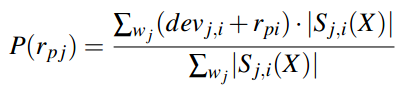
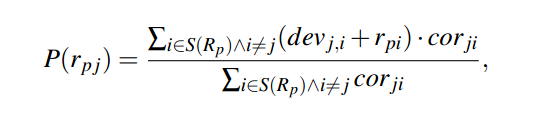


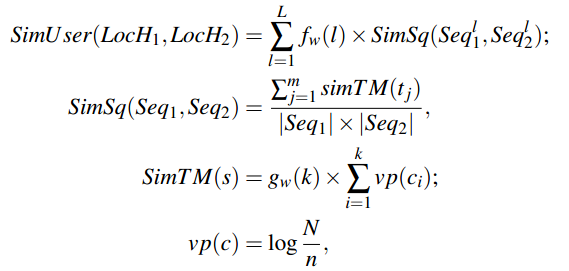


 ,首先算法根据x<1>预测y<1>,然后系统获得y<1>值,然后根据x<2>…以此类推。。在在线学习中,我们感兴趣的是总错误数量,即
,首先算法根据x<1>预测y<1>,然后系统获得y<1>值,然后根据x<2>…以此类推。。在在线学习中,我们感兴趣的是总错误数量,即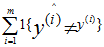 。
。
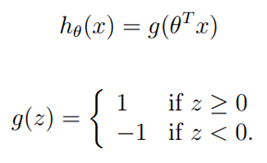
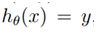 ,参数不变,如果预测错误,对参数进行以下更新:
,参数不变,如果预测错误,对参数进行以下更新:
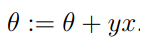
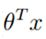 的正负号。
的正负号。
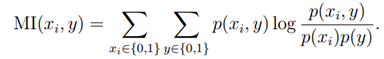
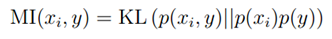
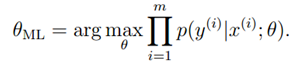
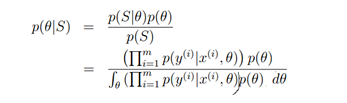
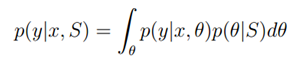
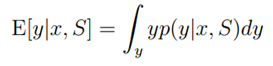
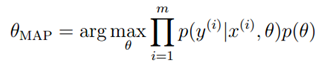
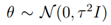 ,这样的话,参数会大部分接近0,这和参数选择的思想是一样的,也就防止了出现过拟合的现象。
,这样的话,参数会大部分接近0,这和参数选择的思想是一样的,也就防止了出现过拟合的现象。
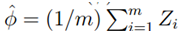 表示这些随机变量的平均值,同时给定常量r,则:
表示这些随机变量的平均值,同时给定常量r,则: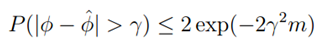
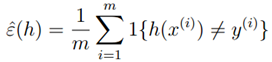
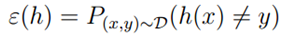
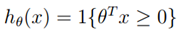 ,一个获得合适的参数?的方法是使训练错误最小,我们称之为经验经验风险最小(ERM)过程。
,一个获得合适的参数?的方法是使训练错误最小,我们称之为经验经验风险最小(ERM)过程。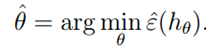
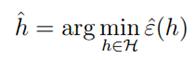
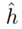 ,真实误差存在上界。
,真实误差存在上界。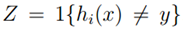 。
。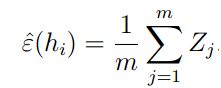
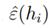 可以理解为m个从独立同分布的伯努利分布的随机变量Zj的平均,而
可以理解为m个从独立同分布的伯努利分布的随机变量Zj的平均,而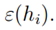 是这个伯努利分布的真实平均值。则由中心极大值定律可知:
是这个伯努利分布的真实平均值。则由中心极大值定律可知: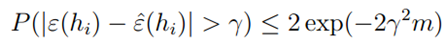
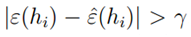 ,则使用联合界限定理,有:
,则使用联合界限定理,有: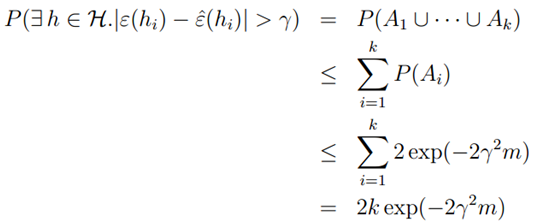
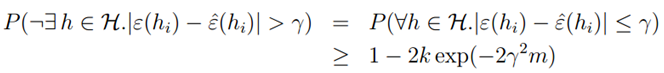
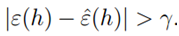 的最大概率界限。同时,我们可以通过两个参数,获得任一个参数的界限。比如给定r和置信度σ,我们需要多少样本量m才能保证在概率1-σ下训练误差和真实误差之差小于r。我们获得了以下公式:
的最大概率界限。同时,我们可以通过两个参数,获得任一个参数的界限。比如给定r和置信度σ,我们需要多少样本量m才能保证在概率1-σ下训练误差和真实误差之差小于r。我们获得了以下公式: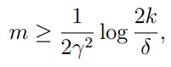
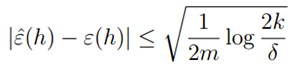
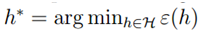 即h*具有最小的真实误差,也就是物理意义上最好的假设函数。假设一致收敛成立,则:
即h*具有最小的真实误差,也就是物理意义上最好的假设函数。假设一致收敛成立,则: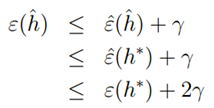
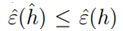 。我们可以获得以下结论:如果一致收敛成立,则
。我们可以获得以下结论:如果一致收敛成立,则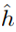 的真实误差最多比最好的假设函数h*差2r。将上式扩展,可得到以下定理:
的真实误差最多比最好的假设函数h*差2r。将上式扩展,可得到以下定理: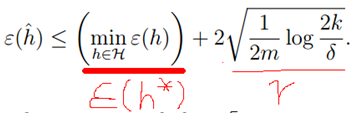
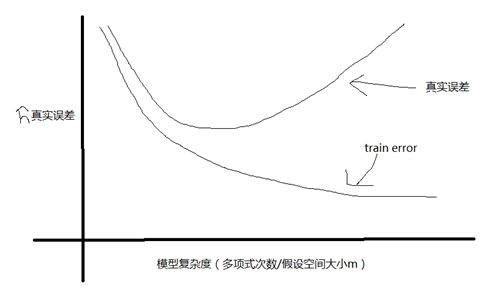
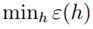 只能减小,因为可能找到一个使误差更小的函数(和偏差对应),但是第二项会增加(方差)。
只能减小,因为可能找到一个使误差更小的函数(和偏差对应),但是第二项会增加(方差)。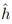 来评估。其实我们最后获得的是
来评估。其实我们最后获得的是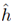 而不是h.
而不是h.