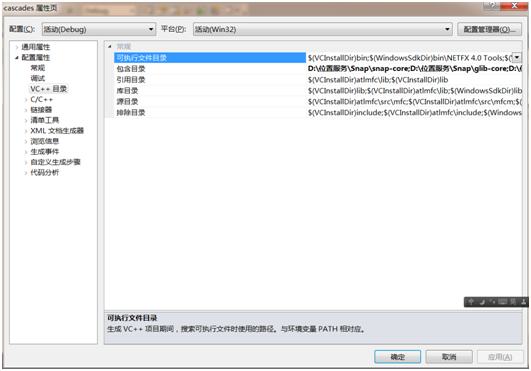
Const修饰变量的主要含义是不能改变该变量的值,为实现最小特权的原则,用于修饰常量以及在函数参数中对其进行限定。
const修饰常量
const int maxvalue=100;
const修饰函数参数指针
为保持最小特权原则,在将指针传给函数的时候,根据函数对指针参数的需要的访问权限,通过const限定有四种方式:
指向非常量数据的非常量指针:可以通过引用指针修改数据,也可以修改该指针使其只想其他数据。
指向常量数据的非常量指针(const char *s):该指针可以被修改为指向其他数据,但是指针指向的数据不能被改变。可以用于传递大型对象,对象在作为参数传递时是按值传递,需要复制对象地址,但是通过指向常量数据的非常量指针,可以通过传递指针获得引用传递的效率,同时获得按值传递的安全性。(应用较广)
指向非常量数据的常量指针:int * const ptr=&x;和数组相同,数组名就是这么一个指针。同时,声明为const的指针必须被初始化。
指向常量数据的常量指针。
const对象、const成员函数和const成员变量
const Time noon(12,0,0)
使用const限定对象不可修改,任何对该对象的修改操作都导致编译错误。
对于const对象,不允许对成员函数调用,除非成员函数也声明为const,即使不修改对象的非const函数也不能被调用。其中,const成员函数必须不能修改对象,也就是说,在定义类的时候,如果某一成员函数不修改对象,可以将其声明为const函数。
声明const成员函数的方法是在声明中和函数定义中说明,在函数头参数列表后插入const关键词。
可以对const函数进行非const版本的重载,即const对象调用const函数,非congst对象调用非const函数。
不允许对构造函数和析构函数进行const声明,const对象的"常量性质"从构造函数完成对象初始化和析构函数开始之间这一过程,也就是说,构造函数和析构函数可以调用非const成员函数。
const成员变量是对象初始化以后不能被改变的变量,而且必须使用成员初始化器进行初始化。成员初始化器列表在构造函数体执行前被执行。
[cpp]
Class Increment
{
Public:
Increment(int c,int i);
Private :
Int count;
Const int increment;
}
Increment::Increment(int c,inti):
count(c),
increment(i)
{
}
[/cpp]
Published:
04 Mar 2013
C++中的模版只要是为了代码重用,模版是为不同类型的变量实现同样的功能,主要分为函数模版和类模版。
和重载的区别和联系:重载是为了不同类型的参数调用不同的函数,并没有代码重用的目的。但是,模版的本质就是重用,在编译阶段,编译器一旦发现使用了某个模版,则针对这个数据类型生成目标代码(模版函数),然后调用之。
函数模版
如printArray()函数用于打印数组,对于不同数据类型的数组次函数的功能几乎相似,如果不使用模版,可使用同样的函数名不同的参数通过重载的形式。而通过函数模版我们只要编码一个函数,编译器会帮助我们自动重载。
使用方法:在函数头前面加上template<typename T>,T是模版类型,用于指定函数实参类型、函数返回值类型或者函数中的变量。
如template<typename T>,或者template<class ElementType>
类模版
在一个实现某个功能类中,希望支持不同的成员变量的类型,比如堆栈类,栈内的元素可以是int型或者float型等等,但是基本的功能是相似的。
使用方法:在类声明前面同样加上template<typename T>。如
[cpp]
template<typename T>;
class Stack{
private: T *stackPtr;
public:
bool pop(T& t);
}
[/cpp]
在类的成员函数的定义时,也需要在前面加上template<typename T>。如:
[cpp]
template<typename T>
bool Stack<T>::pop(T &popValue){
…
}
[/cpp]
实例化一个对象就可以通过:Stack<double> doubleStack(4);
类模版中,可以使用非类型参数和默认类型参数。
非类型参数表示模版形参可以是一个int值,如template<typename T, int elementcout>,使用一下声明:Stack<double,100> hundst;这样,编译时直接把100编译进去。
默认类型参数如template<typename T=string>。声明:Stack<> somestack;
除此以外,如果要存储用户定义的类型,必须提供一个默认的构造函数和重载的赋值运算。如果特定的用户定义类型不能使用通用类模版或有其他特殊处理,可使用显示定义类模版的形式特化。
附:模版和友元的关系以及和静态成员的关系,只要记住模版在编译阶段会根据不同的typename特化为不同的代码。
Published:
03 Mar 2013
嵌套类是在一个类A中定义的类B,类A为外围类,类B为嵌套类。
嵌套类的主要目的在于隐藏类的名字,从而减少全局的标识符,限制并告诫用户是否可以使用该类建立对象。这样提高了抽象能力,并强调了两个类之间的主从关系。
例子:
[cpp title="example.php"]
Class A{
Public:
ClassB{
Public:
…
}
Void f();
Private:
Int a;
}
[/cpp]
在类A的外部,如果要使用初始化B,则使用A::B object_b;
嵌套类仅仅是语法上的嵌入,嵌套类和外部类之间并没有访问权限。
嵌套类的用处:嵌套类就是为了强调嵌套类和外部类的关系,同时减少全局类的数量。比如有两个图类,无向图TUNGraph和有向图TNGraph,它们都有一个嵌套类TNodeI用于遍历节点,如果用全局类的话就要设计两个TNodeI类的名字,可能是TUNodeI和TNodeI,这样不美。而通过嵌套类,只要使用TUNGraph::TNodeI以及TNGraph::TNodeI即可。
Published:
03 Mar 2013
和监督学习相比,监督学习可以针对一个样本定义正确或错误,但是在增强学习的问题中,无法告知agent当前的动作是正确还是错误的。如下棋,对于某一步来说,无法评价这一步是对还是错,只能根据结果,对每一步给定一个评分,告知agent这一步是比较好,还是比较差。
增强学习要解决的问题是:一个能够感知环境的自治agent,如何通过学习选择能达到目标的最优动作。增强学习的目标是获得一个控制策略,以选择能达到目的的行为。
1 马尔科夫决策过程(MDP)
马尔科夫决策过程由五元组{S,A,{Psa},r,R}构成
S表示状态集(states)。
A表示动作集(actions)。
Psa表示状态转移概率。状态s根据动作a转移到其他状态的概率分布。(动作a为s1->s2,并不是说一定转移到s2,还有一定的概率转移到其他状态)
r~[0,1),阻尼系数,代表着离现在越远的状态对现在的影响越小。
R:SxA->R,R是回报函数,回报函数表示状态s进行动作a的评分。因为一个策略对于一个状态的动作是确定的,所以回报函数只与状态有关,可以写为R:S->R
马尔科夫决策过程如下,对于初始状态s0,根据策略选择一个动作a0,执行动作后根据Psa转移到状态s1,一次循环….
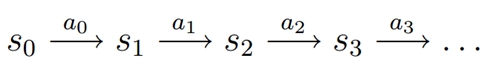
对于状态序列,所有状态的回报之和为:
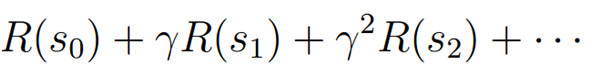
增强学习的目的就是选择一个动作序列(策略),使回报累积期望值最大:
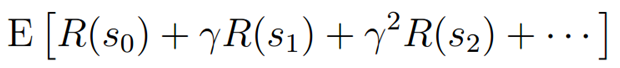
对于一个给定的策略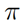 (Pi)的评价函数来评价这个策略的好坏,定义为
(Pi)的评价函数来评价这个策略的好坏,定义为
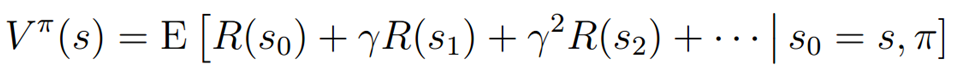
该式满足Bellman等式:
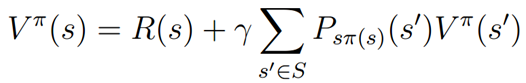
该式说明策略的评价函数包括当前状态的汇报和使用该策略以后的回报期望。
同时,我们定义最优评价函数为:
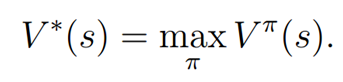
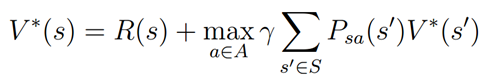
对应最有评价函数,我们定义状态s的最优策略
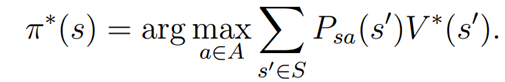
对于不同的初始状态s0,他们的最优策略是一样的。
2值迭代算法和策略迭代算法
下面将介绍两个解决有限状态MDP的高效算法,只考虑具有有限状态和动作的MDP。
值迭代算法

内部循环有两种更新方法:
- 首先计算所有状态的评价值,等此次迭代的所有状态的值计算完成后,一起更新。
- 计算某一个状态的评价值,然后立马更新该状态的评价值。
通过一系列的迭代,最终V将收敛于V,而基于V我们就可以计算出最优策略。
策略迭代:
策略迭代和值迭代相似,只不过策略迭代聚焦于策略,设法使策略Pi收敛到Pi*。

在第二步循环里面,首先基于当前策略计算每个状态的评价值,然后根据所有状态的评价值计算更新策略。其中2(a)步骤可根据bellman等式计算,对于每个状态写一个线性方程,如存在n个状态,则存在n个n元线性方程组成的方程组,可通过解这个方程组计算得到结果。
比较:
两种方法相比,策略迭代更适合较小规模的MDP,而值迭代更适合大规模(状态很多)的MDP,因为值迭代不用求线性方程组。
3 参数估计
在现实数据中,通常状态转移概率和回报函数通常是非已知的,而状态集、动作集和阻尼系数是已经设定好的。因此,我们需要通过已知样本去学习计算状态转移概率和回报函数。
样本格式:
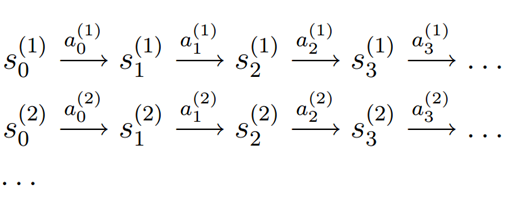
状态转移概率的计算方法为:
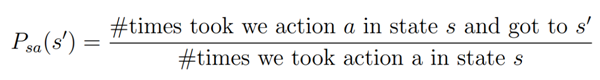
如果回报函数非已知,可使用同样的方法求状态s的观测到的回报的平均值作为该状态的回报。
将参数估计和值迭代结合起来,可以得到以下算法:

Published:
23 Jan 2013
对于独立成分分析(Independent Components Analysis,ICA)希望找到其他维度来表示数据,但是和主成份分析不同在于,主成分分析使用低维度表示高纬度数据,而且样本点符合高斯分布,而独立成分分析并不要求降维,其次样本点不符合高斯分布。
经典的问题是鸡尾酒宴会问题(cocktail party problem)。N个人说话,n个话筒记录。如何把n个人原始的声音分离出来。
形式化描述这个问题:
存在在不同的n个独立源生成的数据s,我们观察到的数据x=As,其中A是未知的方阵,称之为混合矩阵(mixing matrix)。X是一个矩阵,x(i)代表一个向量,表示第i次观察值。通过不断的观察可以获得数据{x|x(i);i=1…m},我们的目标是恢复获得原始源数据s(i),使(x(i)=As(i))。
Published:
07 Jan 2013
2012
上半年(研一下学期)
主要工作有上课、准备托福、修改了一篇论文。
期间,学英语占用了一大部分时间,加上学习课程以及开发设计WEB协商实验。
上半年(3月份开始)原本打算出国,准备了一段时间的托福以后,感觉自己不太喜欢搞科研,英语天赋可能确实不行,准备托福也准备的很痛苦,觉得同时准备托福和论文来不及,放弃,英语水平可能有所长进。总的来说,上半年由于要上课、把大部分课外时间用于准备托福,时间上一直很紧,过的也很痛苦。
下半年(研二上学期)
毕业论文开题,看了好多论文,对科研有了一些基本的认识。尤其是11月以来,几乎所有的时间都花在了上面。
学习《机器学习》,9和10月花了好多时间在这上面,看了一大半了。
看了一些JSp以及ssh框架方面的书,正在开发礼品推荐系统。
8、9月份开始,由于没有课了,也不用准备托福,时间上还是比较轻松的。主要时间用于准备开题了,花了不少时间看论文以及恶补机器学习的相关知识。
十月份以后,做了几个小网站赚了点外快。
看了几本书:
中国人史纲,微观经济学,白鹿原,等等,忘了...
总的来说,对这一年不是很满意,主要原因可能是虽然事情做了不少,没有看得到的成绩。所以开了一个博客,要随时记录自己的工作和收获。同时,以后要把每天做的事情用google calendar记录下来。
2013年展望
2013年最重要的事情——找工作。
参加一个编程比赛。
复习学习各种知识。
看书、学英语
附2011总结
感觉自己应该写一些东西总结一下自己的2011.
流水账:
5月前,跟着george实习,做jsp相关的工作,学习了一些struts和spring框架的知识。后来为了毕业设计,离开了公司。
6-9月,毕业,和同学们疯狂的玩。暑假过的也比较堕落,虽然看了一些书,但是沉淀较少。期间开始接触了一些网站制作的项目,让我对网络上的资金流有了比较全面的了解,大体了解了网站建设的大体流程和运营流程,以及网站盈利的普遍的模式。
9月到1月,研究生学习。期间曾经对微博痴迷了一短时间,曾经尝试过微博营销的一些事情。后来发现浪费时间,也没有啥收获和沉淀,于是放弃了。上课期间主要学习了算法导论和计算机网络,对计算机网络有了一个比较深刻的理解。
嗯,差不多就这么些事情。
收获:
上半年在george那实习,对软件开发流程有了一定的认识,编程能力也有了一些提高。
今年最大的收获就是在非技术层面对IT业有了一定的认识。在以前,所有的眼睛都集中在技术、技术和技术上,现在突然发现除了技术还有其他的东西。比如,IT公司是如何盈利的等等。
渐渐发现自己对产品有很大的兴趣,希望自己做一个产品经理吧,去开发、运营一个自己产品,去观察所处的商业环境,去寻找产品的客户等等。如果想做一个产品经理,我感觉应该是那种什么都懂的,而我对很多东西都有兴趣,以后就朝着方面发展吧,但必然,技术永远是基础,今年打算砸基础。
眼界宽了。
Published:
03 Jan 2013
为解决Hibernate的中文编码问题,需要在三个地方设置,分别是JSP页面,Hibernate框架以及数据库中。
JSP设置<%@?page?language?=?"java"?import?=?"java.util.*"?pageEncoding?=?"utf-8"%>
hibernate设置:<?property?name?="url"?value="jdbc:mysql://localhost:3306/giftr?useUnicode=true&characterEncoding=UTF-8"?/>
MYsql里面表和列需要设置。
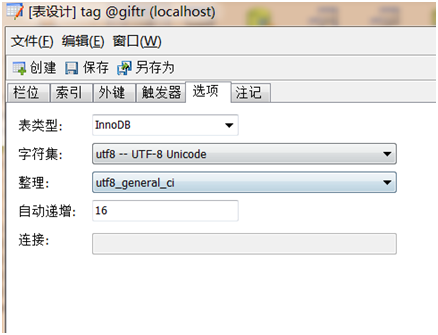
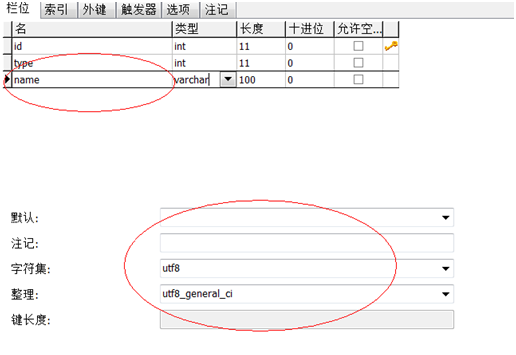
Published:
24 Dec 2012